Denoising Diffusion Implicit Models (DDIM)
Song et. al. (2022) introduced Denoising Diffusion Implicit Models. The concept of DDIM is to apply a new sampling method s.t. the denoising process can be speed up by given a closed form for reverse process.
Recall for DDPM Bayes Derivation
\[\begin{aligned}p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{derive}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{derive}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\xrightarrow{\text{approx}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)\end{aligned}\]We have found that
- Loss function is only related to $p(x_t\vert x_0)$
- Sampling process only rely on $p(x_{t-1} \vert x_t)$, where the reverse process is a markov chain
Therefore, we can make a further assumption based on the derivation result. Can we skip $p(x_t\vert x_{t-1})$ during the derivation process s.t.
\[p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{derive}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{derive}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\]The Methods of Undetermined Coefficient
In short, it is just like let $ax^2+bx+c=0$ …
Recall that we have found \(\begin{align} p(x_{t-1}\vert x_t, x_0) &= \mathbb{N}(x_{t-1}; \mu(x_{t-1}\vert x_t, x_0), \Sigma(x_{t-1}\vert x_t, x_0)) \nonumber \\ &= \mathbb{N}(x_{t-1}; (\sqrt{\bar{\alpha}_{t-1}} - \frac{\alpha_t(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_{t}}) x_{0} + \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_{t}} x_t, \frac{(1-\bar{\alpha}_{t-1})\beta_t}{(1-\bar{\alpha_t})}I) \end{align}\) We just need the model to fulfill marginal probability s.t.
\[\int p(x_{t-1}\vert x_t,x_0)p(x_t\vert x_0)d x_t = p(x_{t-1}\vert x_0)\]Therefore, this time we can more generally let
\[\begin{equation} p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) = \mathcal{N}(\boldsymbol{x}_{t-1}; \kappa_t \boldsymbol{x}_t + \lambda_t \boldsymbol{x}_0, \sigma_t^2 \boldsymbol{I}) \end{equation}\]and form a table as follows: \(\begin{array}{c|c|c} \hline \text{Notation} & \text{Meaning} & \text{Sampling}\\ \hline p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_0) & \mathcal{N}(\boldsymbol{x}_{t-1};\sqrt{\bar{\alpha}_{t-1}} \boldsymbol{x}_0,(1-\bar{\alpha}_{t-1}) \boldsymbol{I}) & \boldsymbol{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \boldsymbol{x}_0 + \sqrt{(1-\bar{\alpha}_{t-1})} \boldsymbol{\varepsilon} \\ \hline p(\boldsymbol{x}_t|\boldsymbol{x}_0) & \mathcal{N}(\boldsymbol{x}_t;\sqrt{\bar{\alpha}_t}\boldsymbol{x}_0,(1-\bar{\alpha}_t) \boldsymbol{I}) & \boldsymbol{x}_t = \sqrt{\bar{\alpha}_t} \boldsymbol{x}_0 + \sqrt{(1-\bar{\alpha}_t)} \boldsymbol{\varepsilon}_1 \\ \hline p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) & \mathcal{N}(\boldsymbol{x}_{t-1}; \kappa_t \boldsymbol{x}_t + \lambda_t \boldsymbol{x}_0, \sigma_t^2 \boldsymbol{I}) & \boldsymbol{x}_{t-1} = \kappa_t \boldsymbol{x}_t + \lambda_t \boldsymbol{x}_0 + \sigma_t \boldsymbol{\varepsilon}_2 \\ \hline {\begin{array}{c}\int p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) \\ p(\boldsymbol{x}_t|\boldsymbol{x}_0) d\boldsymbol{x}_t\end{array}} = p(x_{t-1}\vert x_0) & & {\begin{aligned}\boldsymbol{x}_{t-1} =&\, \kappa_t \boldsymbol{x}_t + \lambda_t \boldsymbol{x}_0 + \sigma_t \boldsymbol{\varepsilon}_2 \\ =&\, \kappa_t (\sqrt{\bar{\alpha}_t} \boldsymbol{x}_0 + \sqrt{(1-\bar{\alpha}_t)} \boldsymbol{\varepsilon}_1) + \lambda_t \boldsymbol{x}_0 + \sigma_t \boldsymbol{\varepsilon}_2 \\ =&\, (\kappa_t \sqrt{\bar{\alpha}_t} + \lambda_t) \boldsymbol{x}_0 + (\kappa_t\sqrt{ (1-\bar{\alpha}_t)} \boldsymbol{\varepsilon}_1 + \sigma_t \boldsymbol{\varepsilon}_2) \\ =& (\kappa_t \sqrt{\bar{\alpha}_t} + \lambda_t) \boldsymbol{x}_0 + \sqrt{\kappa_t^2(1-\bar{\alpha}_t) + \sigma_t^2} \boldsymbol{\varepsilon} \\ \end{aligned}} \\ \hline \end{array}\)
Therefore, we just have 2 equation for 3 unknown, let a free parameter $\sigma^2$ and define:
\[\begin{cases} \sqrt{\bar{\alpha}_{t-1}} &= (\kappa_t \sqrt{\bar{\alpha}_t} + \lambda_t) \\ 1 - \bar{\alpha}_{t-1} &= \sqrt{\kappa_t^2(1-\bar{\alpha}_t) + \sigma_t^2} \\ \end{cases} \\ \begin{align} \kappa_t = \sqrt{\frac{(1-\bar{\alpha}_{t-1})^2 - \sigma_t^2}{1-\bar{\alpha}_t}},\qquad \lambda_t = \sqrt{\bar{\alpha}_{t-1}} - \sqrt{\bar{\alpha}_t}\sqrt{\frac{(1-\bar{\alpha}_{t-1})^2 - \sigma_t^2}{1-\bar{\alpha}_t}} \\ \therefore p_\sigma\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_{t-1} ; \sqrt{\alpha_{t-1}} \mathbf{x}_0+\sqrt{1-\alpha_{t-1}-\sigma_t^2} \frac{\mathbf{x}_t-\sqrt{\alpha_t} \mathbf{x}_0}{\sqrt{1-\alpha_t}}, \sigma_t^2 \mathbf{I}\right) \end{align}\]Freedom on Variance $\sigma^2_t$
We can observe that we have a new hyperparameter $\sigma^2_t$. We can take some example from previous blog.
1. Take \(\sigma^2_t=\frac{(1-\bar{\alpha}_{t-1})\beta_t}{(1-\bar{\alpha_t})}\) (Same as DDPM)
The paper in DDIM has discussed the performance when \(\sigma^2_t= \eta\frac{(1-\bar{\alpha}_{t-1})\beta_t}{(1-\bar{\alpha_t})}, \eta \in [0,1]\)
2. Take $\sigma^2_t=0$
By letting \(\sigma^2_t=0\) and starting at \(x_\tau=z\) , the reversed pass process will become deterministic, meaning that model will generate predicted \(x_0\) directly.
Speed up from Non-Markov Inference Pass

We can observe that we skipped
\(p(x_t\vert x_{t-1})\)
.
\(\alpha_t\)
and
\(\bar{\alpha}_t\)
is deterministic and are hyperparameters. As denoising objective
\(\left\Vert\boldsymbol{\varepsilon} - \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\bar{\alpha}_t \boldsymbol{x}_0 + \bar{\beta}_t \boldsymbol{\varepsilon}, t)\right\Vert^2\)
(which describe we want a model to predict $x_0$ from $x_t$) does not depend on the specific forward procedure as long as $p(x_t|x_0)$ is fixed, we may also consider forward processes with lengths smaller than T, which accelerates the corresponding generative processes without having to train a different model.
In DDIM view, if we have trained $x_1, x_2, \dots, x_{1000}$ to predict $x_0$, meaning we have 1000 model that train to map $x_1 \rightarrow x_0, x_2 \rightarrow x_0, \dots, x_{1000} \rightarrow x_0$.
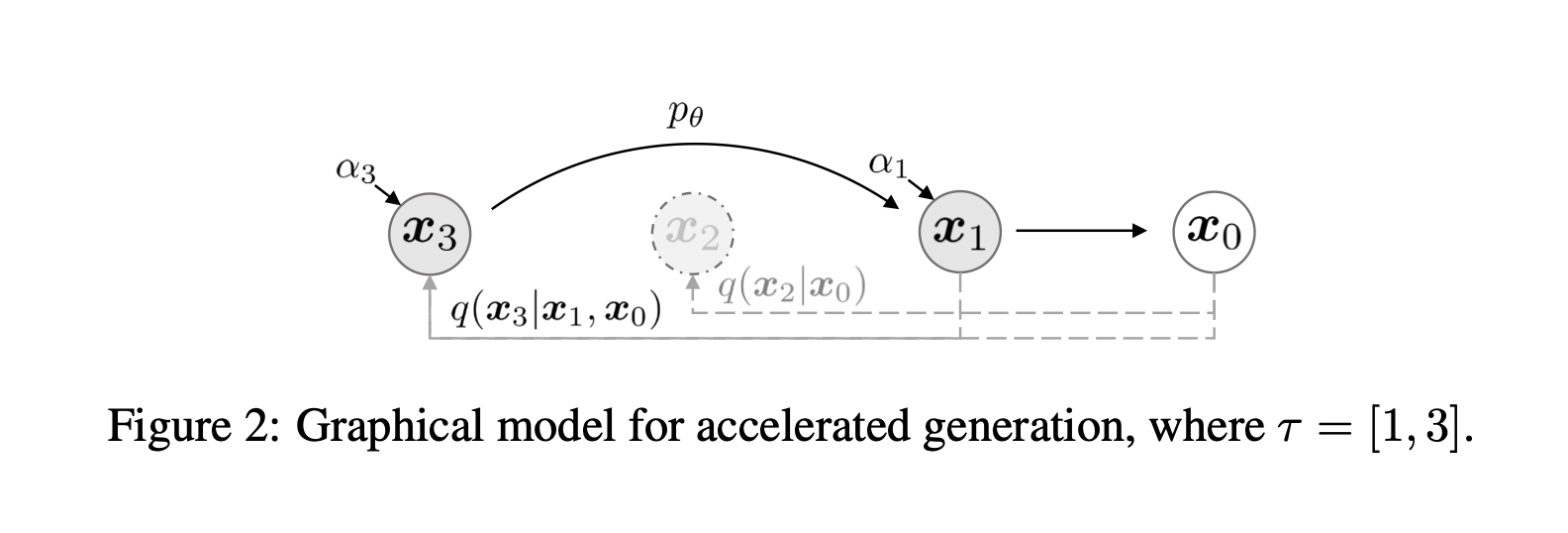
More specifically, we let $\mathbf{\tau} = [\tau_1, \tau_2, \dots, \tau_{dim(\tau)}]$ as an arbitary subset of $[1,2,\dots,T]$ of length $S$. For a well-pretrained diffusion model, the model include the result for any arbitary subset $\mathbf{\tau}$.
Vice versa, we can treat a DDPM with $T$ step is a superset of $\mathbf{\tau}$. If so, we can generate a new image with only $dim(\tau)$ steps.
But dont we train a model with only $dim(\tau)$ step?
In principle, this means that we can train a model with an arbitrary number of forward steps but only sample from some of them in the generative process.
Performance in Different Distribution
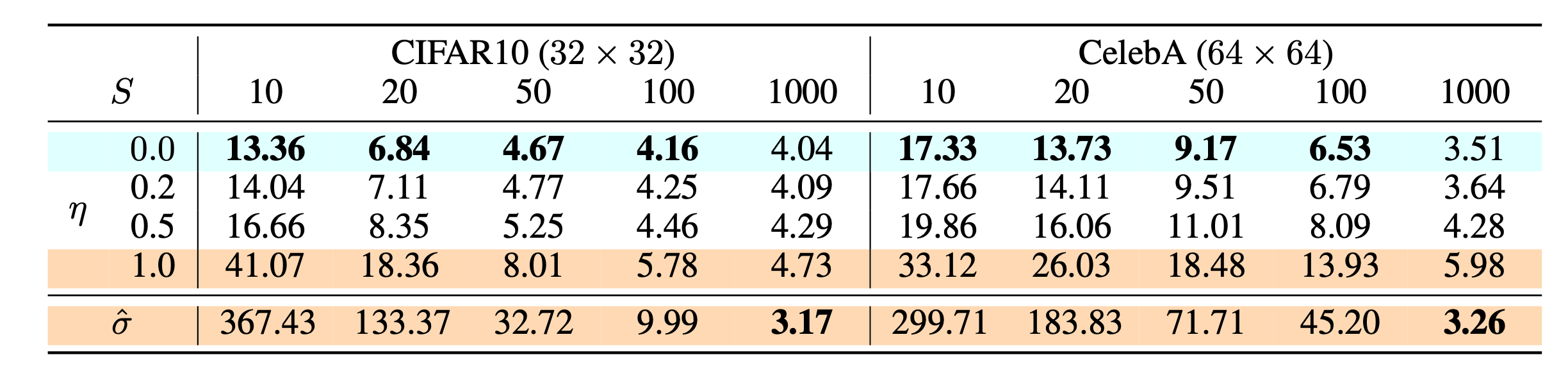
The paper in DDIM has discussed the performance in different setting of $\eta$ and $S$, where $S$ means timestep and $\eta$ is a hyperparameter to scale the randomness.
\(\sigma^2_t= \eta\frac{(1-\bar{\alpha}_{t-1})\beta_t}{(1-\bar{\alpha_t})}, \eta \in [0,1]\)
In experiment, both DDPM($\eta=1$) and DDIM($\eta=0$) is trained with T=1000. They observed that DDIM can produce the best quality samples when $S=dim(\tau)$ is small while DDPM does perform better when we can afford to run the full reverse Markov diffusion steps $(S=T=1000)$.
-
Previous
Review: Denoising Diffusion Probabilistic Models (DDPM) -
Next
Review: High-Resolution Image Synthesis with Latent Diffusion Models (LDM)